We create estimates for your genetic ethnicity by comparing your DNA to the DNA of other people who are native to a region. The AncestryDNA reference panel (version 2.0) contains 3,000 DNA samples from people in 26 global regions.
We build the reference panel from a larger reference collection of 4,245 DNA samples collected from people whose genealogy suggests they are native to one region. The images below show the process of gathering local samples from various parts of the world.
Each panel member’s genealogy is documented so we can be confident that their family is representative of people with a long history (hundreds of years) in that region.Each volunteer’s DNA sample from a given region is then tested and compared to all others to construct the AncestryDNA reference panel. In the end, 3,000 of 4,245 individuals are chosen for the AncestryDNA reference panel (version 2.0). These individuals make up 26 global regions.
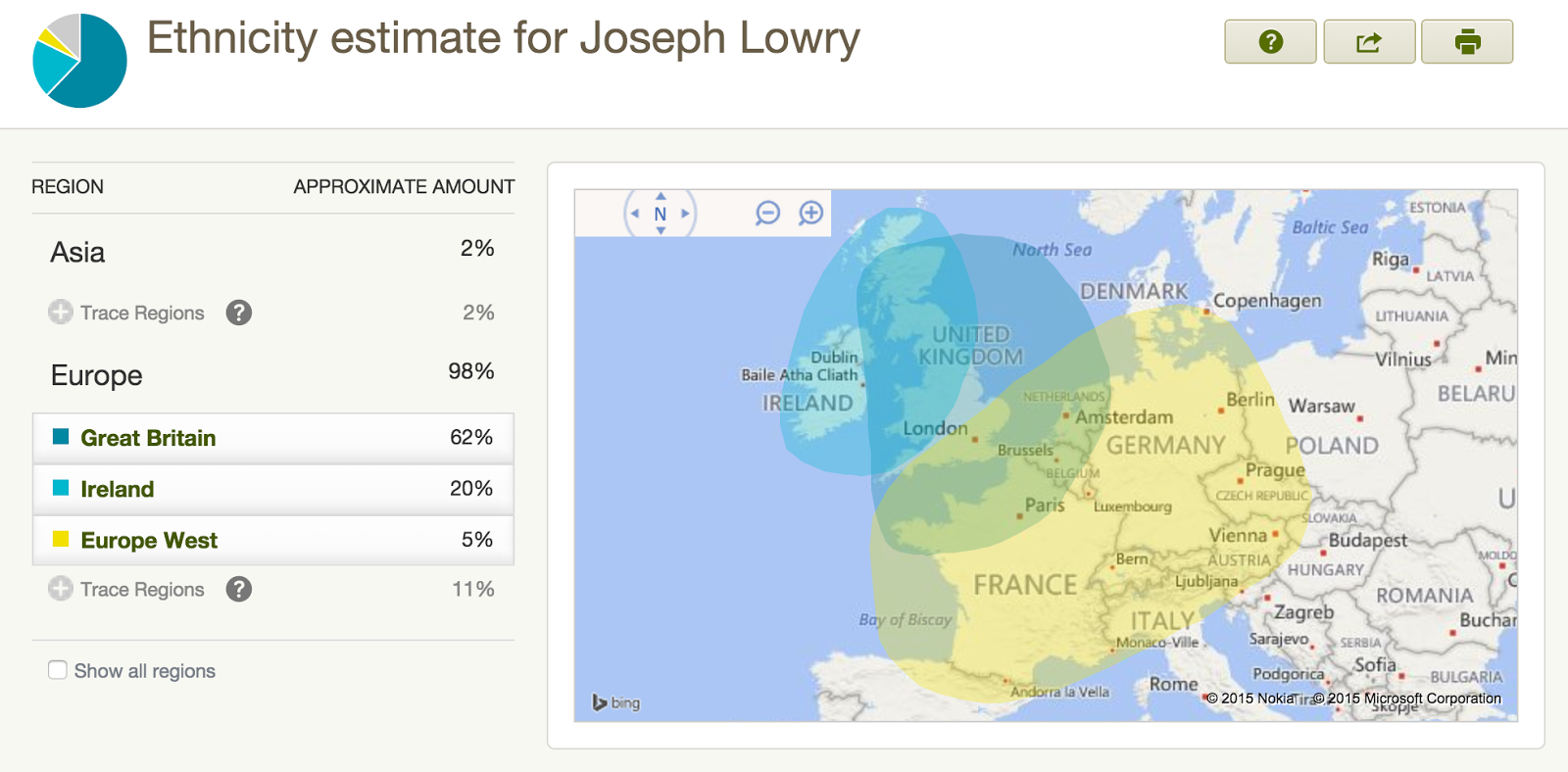
We then compare your DNA to the DNA in the reference panel to see which regions your DNA is most like. The ethnicity estimate you see on the web site is the result of this comparison. When we calculate your estimate for each ethnicity region, we run forty separate analyses. Each of the forty analyses gives an independent estimate of your ethnicity, and each one is done with randomly selected portions of your DNA. Your genetic ethnicity estimates and likely ranges for these estimates come from these forty analyses.[1]
We assembled a large number of candidate reference populations which were relatively unadmixed and sampled widely in terms of geography. From these we removed related or outlier individuals with the Plink software, utilizing identity-by-descent (IBD) analysis and visually inspecting multi-dimensional scaling plots (MDS). Further visualization established that the reference population sets were indeed genetically distinct from each other. We also ran Admixture and MDS with specific populations to asses if any individuals were outliers or exhibited notable gene flow from other reference groups, removing these. Admixture was run on an inter and intra-continental scale to establish a plausible number of K values utilizing the cross-validation method [Alexander2011]. After removing markers which were missing in more than 5 percent of loci and those with minor allele frequencies below 1 percent, the total intersection of SNPs across the pooled data set was 290,874. The final number of individuals in was 1,353.
To validate our Reference Population set we tested them against a list of well studied benchmark groups whose ancestral background in the literature has been well attested. Additionally we also cross-checked against individuals with attested provenance within the GeneByGene DNA database.[2]
So both companies test their results against certain population groups who they believe have remained relatively static over time. Still, once I checked my result, I was again surprised and this time for entirely different reasons.

Sources:
Ball, Catherine A., Mathew J. Barber, Jake K. Byrnes, Josh Calloway, Kenneth G. Chahine, Ross E. Curtis, Kenneth Freestone, Julie M. Granka, Natalie M. Myres, Keith Noto, Yong Wang, and Scott R. Woodward. “Ethnicity Estimate White Paper.” Ancestry.com (2013): n. pag. 30 Oct. 2013. Web. 17 Feb. 2015.
Khan, Razib, and Rui H. “MyOrigins Methodology Whitepaper – FTDNA Learning Center.” FTDNA Learning Center. Family Treee DNA, 8 May 2014. Web. 17 Feb. 2015.

[…] cousins through this service. I will be the first to admit that I am an AncestryDNA customer. As I wrote about here, I took one of their DNA tests and as a result, I have in fact connected with several new […]
LikeLike